基于内存实现
由于是存储在内存中的数据库, 不会被磁盘 IO 影响到数据读写的效率, 也就是说减少了磁盘 IO 的开销
高效的数据结构
SDS
1. 字符串长度处理
存储了 len 这个字段以快速获取长度
2. 内存重新分配
- 空间预分配 分配必须的空间之外, 还会额外分配未使用空间 len < 1M, 额外分配 len 长度的空间 len > 1M, 额外分配 1M 长度的空间
- 惰性空间释放 使用完毕的空间, 不会直接进行回收, 而是使用 free 字段将多余的空间存储下来, 后续使用空间可以先从 free 中获取, 减少内存分配
3. 不需要处理二进制安全 ‘\0’
根据 len 来判断 字符串 结束, 不需要额外的处理来判断字符串结束
双端链表
1. 前后节点
listNode 中存储 prev 和 next 加快获取前后节点的速度
2. 头尾节点
list 中存储 head 和 tail 方便正序或者逆序遍历链表
同时双端节点的处理时间降至 O(1)
3. 链表长度
同 SDS 的 len, O(1) 获取长度
压缩列表
优化链表存储时, 每次都需要存储是都需要保存一些重复的信息, 如头节点, 前后节点, 这样会浪费空间, 反复申请释放也容易导致内存碎片化
而压缩列表操作是通过指针与解码出的偏移量进行的, 效率更高
同时内存是连续分布的, 遍历速度快
字典
哈希表原理, O(1)时间查找和插入
跳表
多级索引加快效率
合理的数据编码
embstr 和 raw 的区别
embstr: 保存比较短的字符串, 只需要申请一次内存分配函数, 因为在创建 RedisObject 和 sdshdr 时是直接一起创建的连续内存, 释放一次内存
raw: 保存比较长的字符串, 使用时需要为 RedisObject 和 sdshdr 都申请一次内存分配函数, 需要释放两次内存
Redis 中 embstr 和 raw 编码的界限
1. 结论
在 redis 4.0 之前, 代码创建的逻辑是与REDIS_ENCODING_EMBSTR_SIZE_LIMIT = 39 进行比较,如果小于 39 的话创建的是 embstr ,否则为 raw
但在 5.0 中 修改成了当小于 44 个字节的时候使用 embstr,大于 44 的时候为 raw
2. 原因创建 stringObject 的逻辑
redisObject, 需要占据 16 个字节
typedef struct redisObject {
unsigned type:4; //对象类型(4位=0.5字节)
unsigned encoding:4; //编码(4位=0.5字节)
unsigned lru:LRU_BITS;//记录对象最后一次被应用程序访问的时间(24位=3字节)
int refcount; //引用计数。等于0时表示可以被垃圾回收(32位=4字节)
void *ptr; //指向底层实际的数据存储结构,如:SDS等(8字节)
} robj;sdshdr, len 和 free 需要占据 8 个字节, /0 占据 1字节
所以 buff 最多占用 64 – 16 – 9 = 39, 即 embstr 编码字符串 内容长度最多 39 字节
struct sdshdr {
unsigned int len;
unsigned int free;
char buf[];
};因为unsigned int 太过于宽泛, 所以将 sdshdr 细分成了 sdshdr8, sdshdr16, 32,64, 也就是说原来的
unsigned int len 和 unsigned int alloc(占 8 个字节) 变成了 uint8_t len 和 uint8_t alloc (占 2 个字节)
然后增加了一个 char flag, 即最后原来的 8 字节 优化成了 3 字节, 即多出了 5 字节给 buf, 所以优化成了 embstr 编码字符串长度为 39 + 5 = 44 字
在代码中就是
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
if (len < OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr, len);
else
return createRawStringObject(ptr, len);合适的线程模型
1. I/O多路复用模型
- I/O: 网络 I/O
- 多路: 多个 TCP 链接
- 复用: 公用一个线程或进程
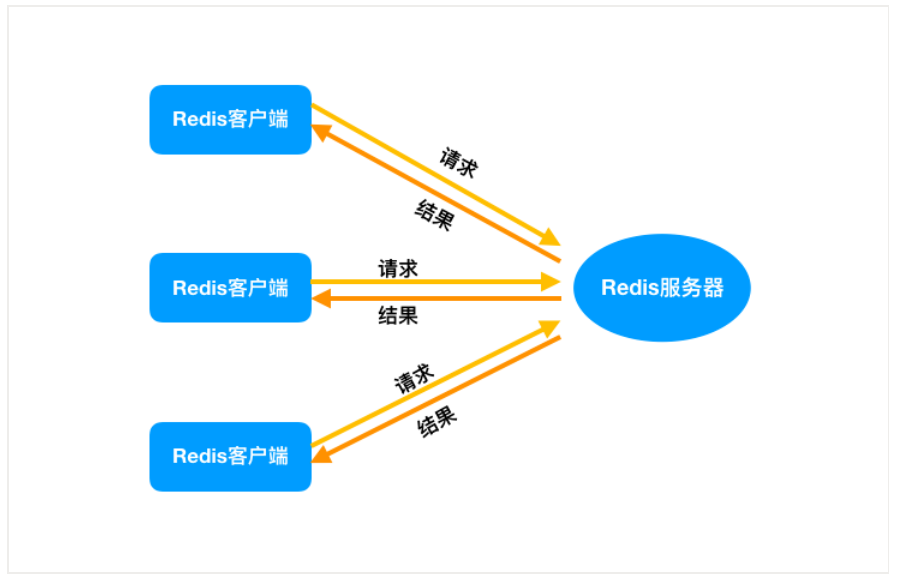
生产环境中, 通常是多个客户端连接 Redis,然后各自发送命令至 Redis 服务器,最后服务端处理这些请求返回结果。
应对大量的请求,Redis 中使用 I/O 多路复用程序同时监听多个套接字,并将这些事件推送到一个队列里,然后逐个被执行。最终将结果返回给客户端
2. 避免上下文切换
因为 Redis 是单线程的, 在执行过程中不需要进行 CPU 的上下文切换, 多次读写都是在一个 CPU 上, 效率很高
多线程在执行过程中需要进行 CPU 的上下文切换
3. 单线程模型
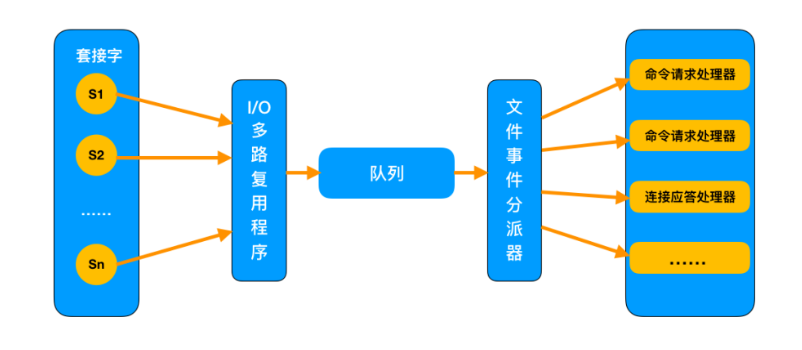
因为 Redis 使用了 Reactor 单线程模型, 接收到用户的请求后,全部推送到一个队列里,然后交给文件事件分派器,而它是单线程的工作方式。Redis 又是基于它工作的,所以说 Redis 是单线程的。
Redis 的瓶颈
纯内存访问,所有数据都在内存中,所有的运算都是内存级别的运算,内存响应时间的时间为纳秒级别。因此 redis 进程的 cpu 基本不存在磁盘 I/O 等待时间、内存读写性能问题,CPU 不是 redis 的瓶颈(内存大小和网络I/O 才是 redis 的瓶颈,也就是客户端和服务端之间的网络传输延迟)。