基本概念
允许快速查询一个有序连续元素的数据链表。跳跃列表的平均查找和插入时间复杂度都是O(log n),优于普通队列的O(n)。
动态查找的数据结构
可以作为查找数据结构的包括:
- 线性结构:数组、链表
- 非线性结构:平衡树
数组结构
缺点: 移动和删除时需要整体移动
优点: 内存连续, 查找方便
链表
缺点: 查找比较慢, 需要遍历而中间经过的节点, 就算我知道节点的大概位置, 也只能一步步到终点位置, 所以这是个可以优化的地方
平衡树
缺点: 需要存储的内容很多, 复杂的结构增加了调整平衡树的难度
优点: 处理动态查找问题也是可以的, 并且可以存储父子兄弟节点, 存储的信息很多
跳表的雏形
- 可以看到, 因为数组的内存连续性还有树的平衡树的多节点关系决定了他们不好改造, 而链表最适合被改造
- 链表插入和删除都很简单, 但是搜索时却需要步步遍历, 明明可以一步到位可偏偏得走很多步, 这就是可以优化的地方
- 即给链表加索引, 这就是跳表的由来
跳跃链表的实现原理
简单索引
- 给偶数多添加一个指针, 指向下一个偶数

多级索引
- 基于偶数节点增加索引并且只有两层的情况下,最高层的节点数是
n/2,整体来看搜索的复杂度降低为O(n/2),并不要小看这个1 / 2 的系数,看到这里会想 增加索引层数到 k ,那么复杂度将指数降低为O(n/2^k) - 索引层数也不能无限增加, 如果索引节点数量等于 2 , 那么再增加也没有意义了(因为两个节点怎么样查找都需要走两步)
索引层数和索引节点密度
当索引节点数量太少时将退化为普通链表, 而当索引节点数量太大时也是一样
太少和太多的索引节点都是一样的低效率
跳表的复杂度分析
时间复杂度分析
- 复杂度与
索引层数 m , 索引节点间隙 d有直接关系 - 假如链表有 n 个节点, 那么就可以推出时间复杂度, 如下图
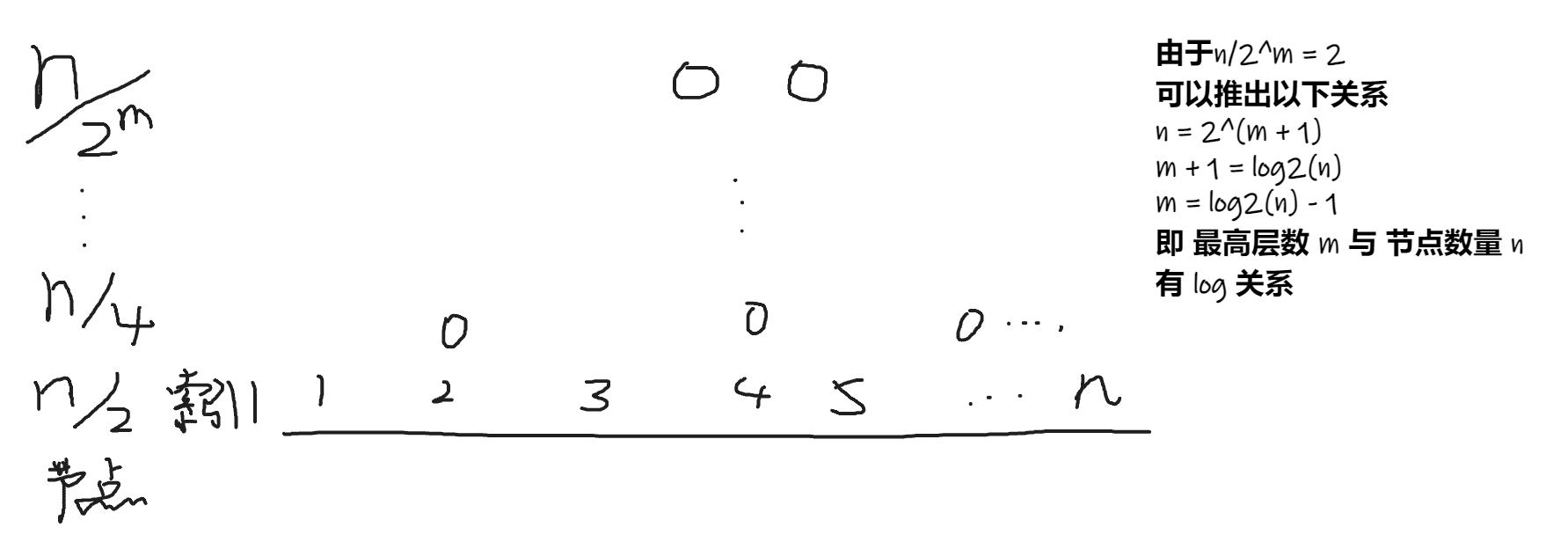
- 如果每一层需要遍历的节点数为 d , 那么整个的时间复杂度为
O(d*logn)
跳表的空间存储
- 以 d = 2 情况来计算, 索引节点总数为
2 + 4 + 8 + ... + n / 4 + n / 2 - 由等比数列求和公式可得所需额外空间为
n - 2 - 即额外空间消耗为
O(n - 2)
跳表在 Redis 中的应用
- ZSet结构同时包含一个字典和一个跳跃表,跳跃表按score从小到大保存所有集合元素。字典保存着从member到score的映射。这两种结构通过指针共享相同元素的member和score,不会浪费额外内存

跳表随机层数的实现原理
- 跳表是一个概率型的数据结构,元素的插入层数是随机指定的
- 指定节点最大层数 MaxLevel,指定概率 p, 默认层数 lvl 为1
- 生成一个 0 – 1 的随机数 r , 若 r < p , 且 lvl < MaxLevel, 则 lvl ++
- 重复上一步, 直到 r > p 为止, 此时的 lvl 就是要插入的层数
Redis 中的跳表也是类似的原理, 不过有一些处理的差距
Redis 关于跳表的源码
// src/z_set.c
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}两个宏定义
// redis.h
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^32 elements */
#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */&0xFFFF 是代表 1111 1111 1111 1111 , 也就是说, 他与 random() 随机数与运算之后, 得到的还是 random()
*0xFFFF 也是类型转换, 编译器中0xFFFF是默认无符号数, 所以转换为 uint_32
所以可以有以下推论
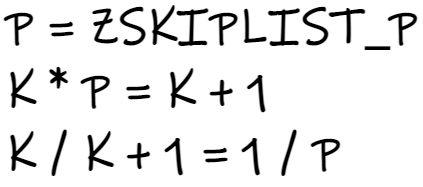
也就是说k层节点的数量是k+1层节点的1/ZSKIPLIST_P 倍
所以 redis 中的 跳表相当于一颗四叉树